
第5篇
第5篇
在本篇随笔中,我们主要介绍:
- 对于正则表达式的处理
本篇随笔同步于博客园:{暂未同步}
老师上课给的例子
在上课的时候,老师给出来了一个正则表达式文法,见下:
url ::= 'http://' hostname (':' port)? '/'
hostname ::= word '.' hostname | word '.' word
port ::= [0-9]+
word ::= [a-z]+
接着老师用这套文法去识别了一个字符串:http://didit.csail.mit.edu:4949/,过程如下图所示:
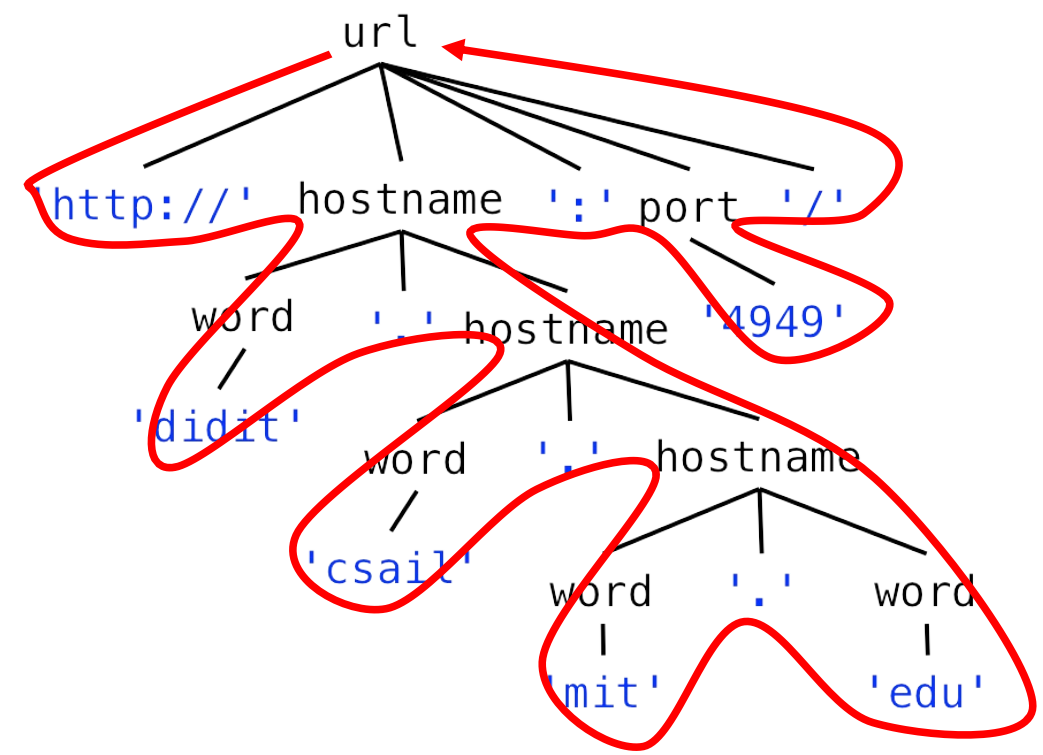
老师说,Java在解析这个串的过程中,用到了栈结构,这让我联想到了形式语言与自动机这门课程中所讲述的文法转PDA相关知识,于是将我想的一个可能的处理过程列在下面。
可能的处理过程
1.根节点为url,此时还没有对字符串进行任何处理。

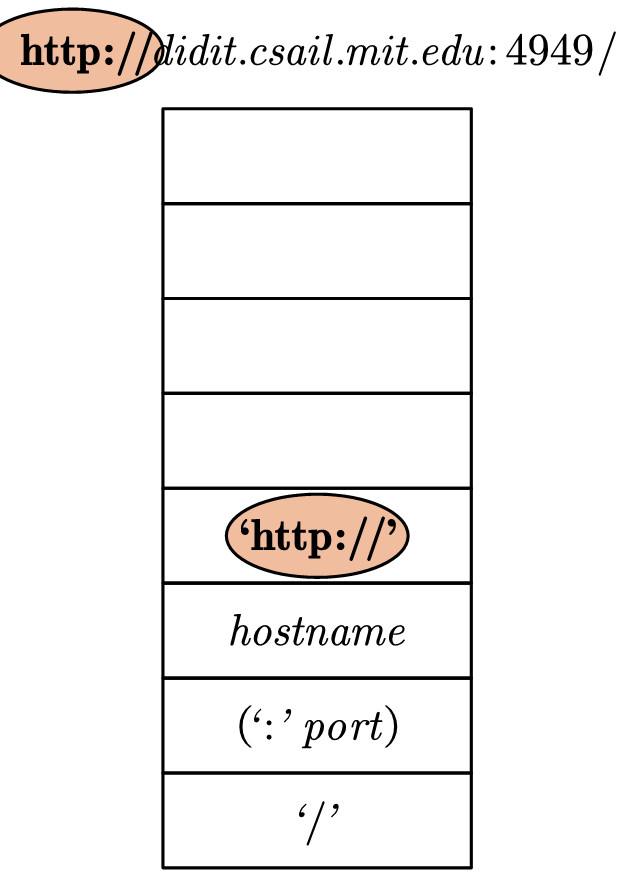
2.将url弹出,并将url对应的规则弹入。此时注意到,栈顶的https://字符串刚好可以和欲匹配字符串的开头匹配。
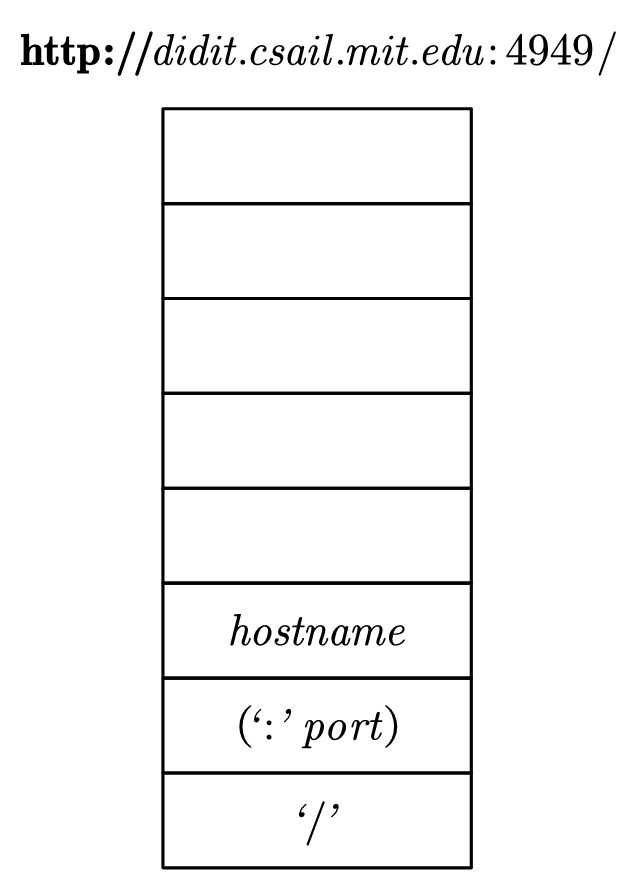
3.将https://弹出,此时对于欲匹配字符串来说,我们已经匹配了开头的https://了,接下来匹配剩余的部分就好。
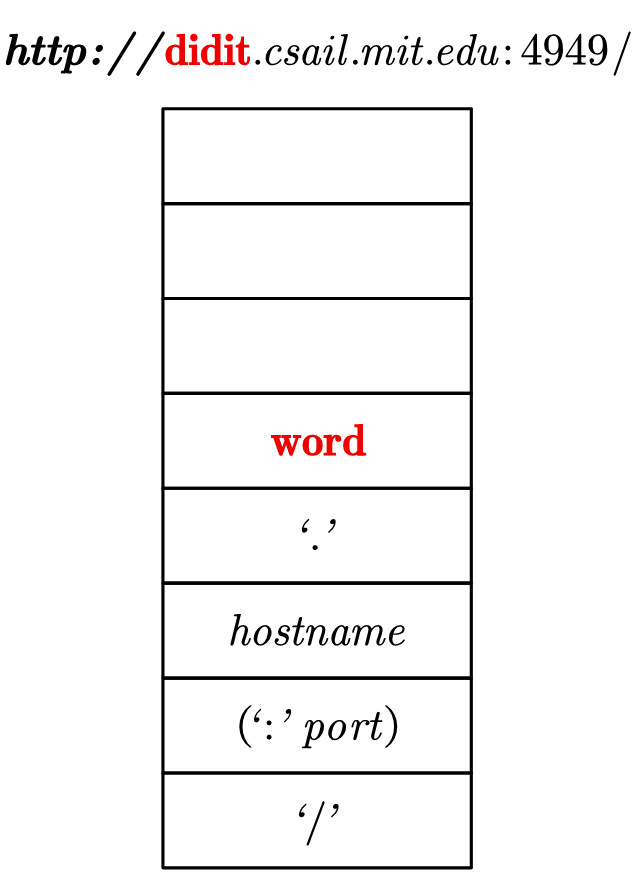
4.将栈顶的hostname弹出,将其规则word '.' hostname压入栈。此时注意到,欲匹配字符串的剩余部分的开头,即didit,是可以和目前栈顶word相匹配的。
5.弹出word。此时注意到,欲匹配字符串的剩余部分的开头,即.,是可以和目前栈顶.相匹配的。

6.弹出.。
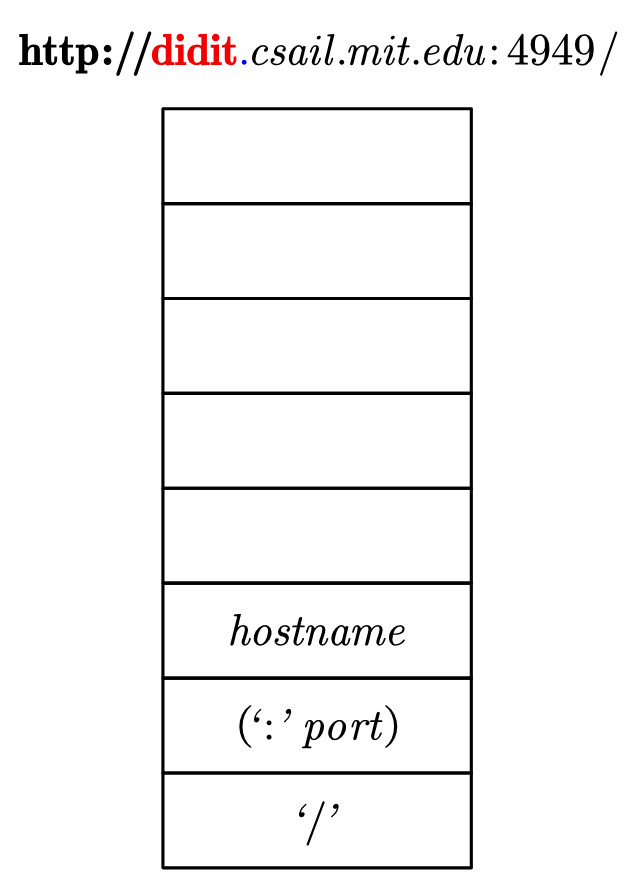
7.重复4~6步,可以将欲匹配字符串中的csail.也给匹配掉
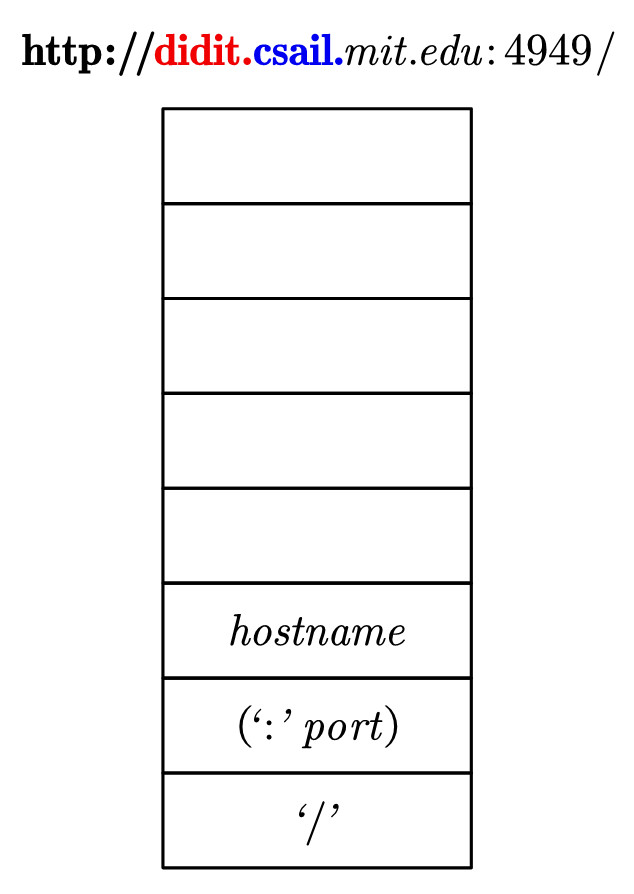
8.将栈顶的hostname弹出,将其规则word '.' word压入栈。此时注意到,欲匹配字符串的剩余部分的开头,即mit,是可以和目前栈顶word相匹配的。
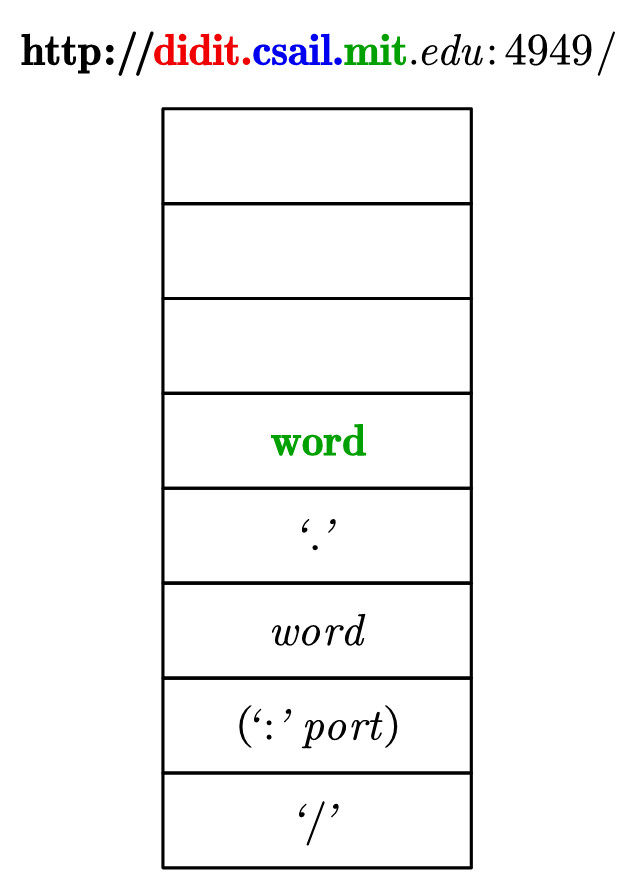
9.弹出word。此时注意到,欲匹配字符串的剩余部分的开头,即.,是可以和目前栈顶.相匹配的。
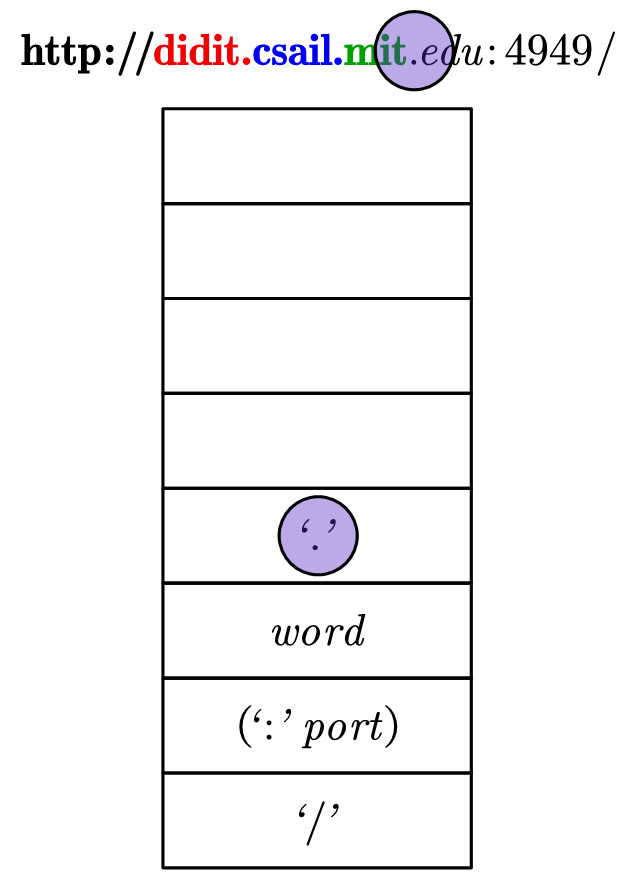
10.弹出.。此时注意到,欲匹配字符串的剩余部分的开头,即edu,是可以和目前栈顶word相匹配的。
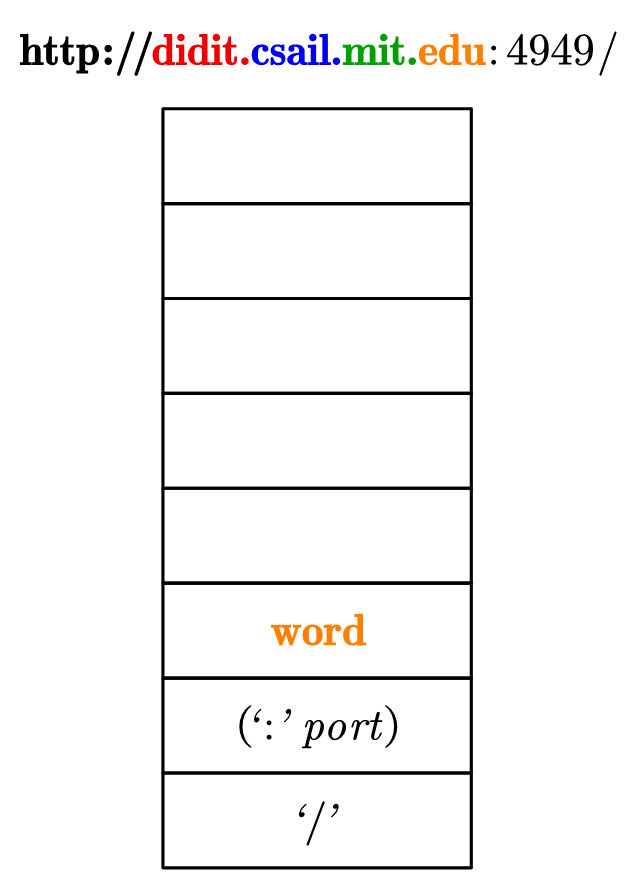
11.弹出edu。此时注意到,欲匹配字符串的剩余部分的开头,即:4949,是可以和目前栈顶(':' port)?相匹配的。

12.弹出(':' port)?。此时注意到,欲匹配字符串的剩余部分的开头,即/,是可以和目前栈顶'/'相匹配的。

13.弹出'/'。此时欲匹配字符串已经匹配完了,恰好栈中刚好全空,因而匹配成功。
